READING GROUP
Generating Videos
with Scene Dynamics
Chaoran Huang, chaoranh@cse.unsw.edu.au
Generating Videos with Scene Dynamics
NIPS 2016

Carl Vondrick
rich predictive models
computer vision and machine learning
Ph.D. Student, MIT
https://github.com/cvondrick
Generative Adversarial Networks
Spatio-temporal 3D Models
Discriminator Network (D)
Video Generator Network (G)
apply SGD on:

One Stream Architecture
Consistent in both time and space
Low dimension input, high dimension output
Only object moves
Two Stream Architecture
Enforced static background (picture )
Moving foreground
Summarize with mask


Data
2 years of Flickr Videos
9 TB, 35 million clips
5,000+ hours length
26 TB raw data
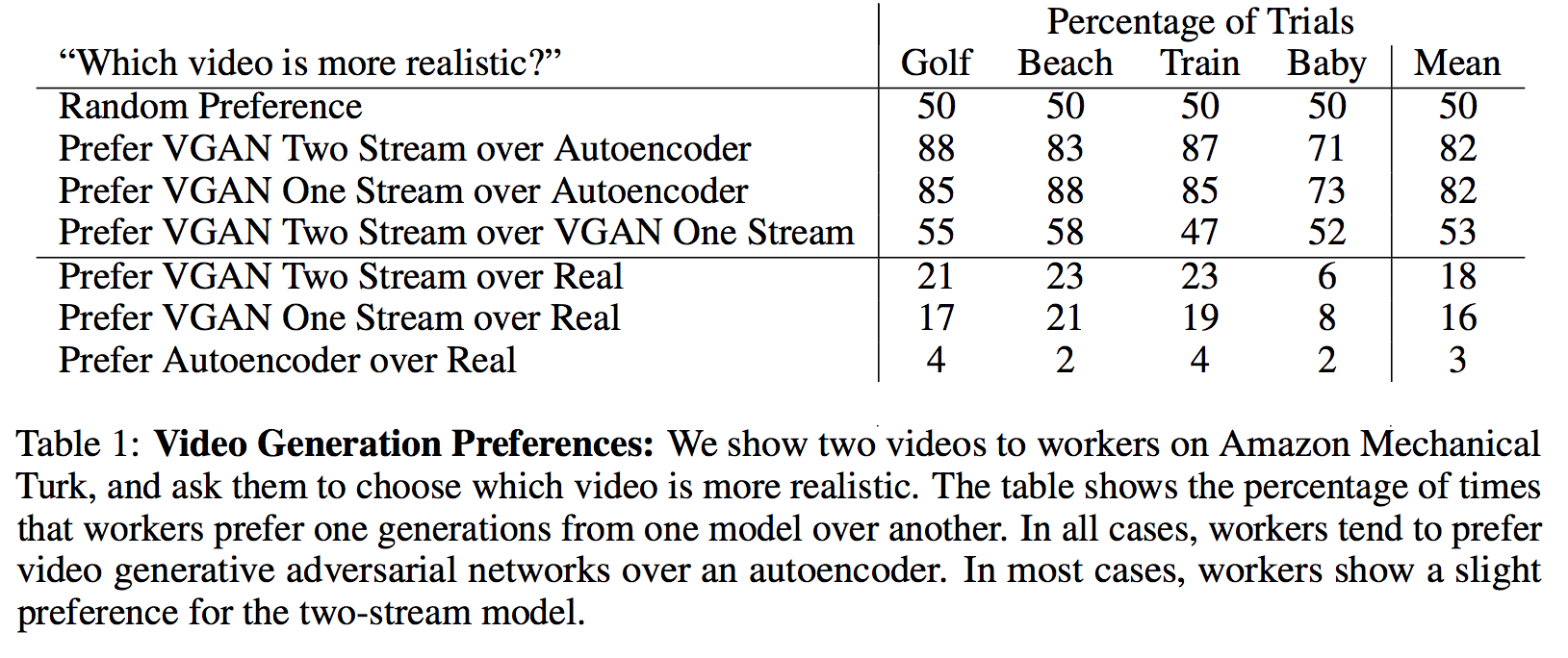

End
